
Demystifying Kubeflow pipelines: Data science workflows on Kubernetes – Part 1

Rui Vasconcelos
on 24 June 2020
Tags: AI , deep learning , Kubeflow , machine learning , MLOps , pipeline
Kubeflow Pipelines are a great way to build portable, scalable machine learning workflows. It is one part of a larger Kubeflow ecosystem that aims to reduce the complexity and time involved with training and deploying machine learning models at scale.
In this blog series, we demystify Kubeflow pipelines and showcase this method to produce reusable and reproducible data science. 🚀
We go over why Kubeflow brings the right standardization to data science workflows, followed by how this can be achieved through Kubeflow pipelines.
In part 2, we will get our hands dirty! We’ll make use of the Fashion MNIST dataset and the Basic classification with Tensorflow example, and take a step-by-step approach to turn the example model into a Kubeflow pipeline so that you can do the same.
Why use Kubeflow?
A machine learning workflow can involve many steps and keeping all these steps in a set of notebooks or scripts is hard to maintain, share and collaborate on, which leads to large amounts of “Hidden Technical Debt in Machine Learning Systems”.
In addition, it is typical that these steps are run on different systems. In an initial phase of experimentation, a data scientist will work at a developer workstation or an on-prem training rig, training at scale will typically happen in a cloud environment (private, hybrid, or public), while inference and distributed training often happens at the Edge.

Containers provide the right encapsulation, avoiding the need for debugging every time a developer changes the execution environment, and Kubernetes brings scheduling and orchestration of containers into the infrastructure.
However, managing ML workloads on top of Kubernetes is still a lot of specialized operations work which we don’t want to add to the data scientist’s role. Kubeflow bridges this gap between AI workloads and Kubernetes, making MLOps more manageable.
What are Kubeflow Pipelines?
Kubeflow pipelines are one of the most important features of Kubeflow and promise to make your AI experiments reproducible, composable, i.e. made of interchangeable components, scalable, and easily shareable.
A pipeline is a codified representation of a machine learning workflow, analogous to the sequence of steps described in the first image, which includes components of the workflow and their respective dependencies. More specifically, a pipeline is a directed acyclic graph (DAG) with a containerized process on each node, which runs on top of argo.
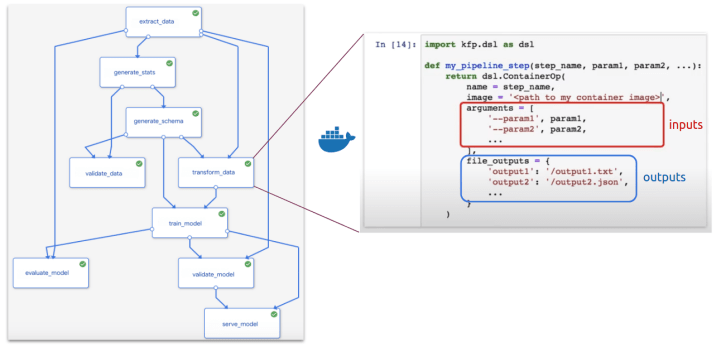
Each pipeline component, represented as a block, is a self-contained piece of code, packaged as a Docker image. It contains inputs (arguments) and outputs and performs one step in the pipeline. In the example pipeline, above, the transform_data step requires arguments that are produced as an output of the extract_data and of the generate_schema steps, and its outputs are dependencies for train_model.
Your ML code is wrapped into components, where you can:
- Specify parameters – which become available to edit in the dashboard and configurable for every run.
- Attach persistent volumes – without adding persistent volumes, we would lose all the data if our notebook was terminated for any reason.
- Specify artifacts to be generated – graphs, tables, selected images, models – which end up conveniently stored on the Artifact Store, inside the Kubeflow dashboard.
Finally, when you run the pipeline, each container will now be executed throughout the cluster, according to Kubernetes scheduling, taking dependencies into consideration.
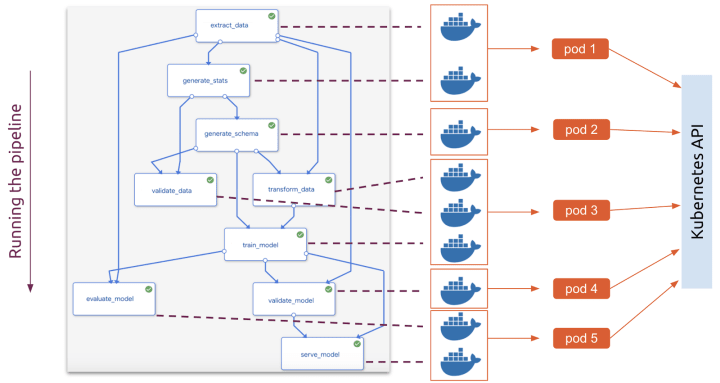
This containerized architecture makes it simple to reuse, share, or swap out components as your workflow changes, which tends to happen.
After running the pipeline, you are able to explore the results on the pipelines interfaces, debug, tweak parameters, and run experiments by executing the pipeline with different parameters or data sources.
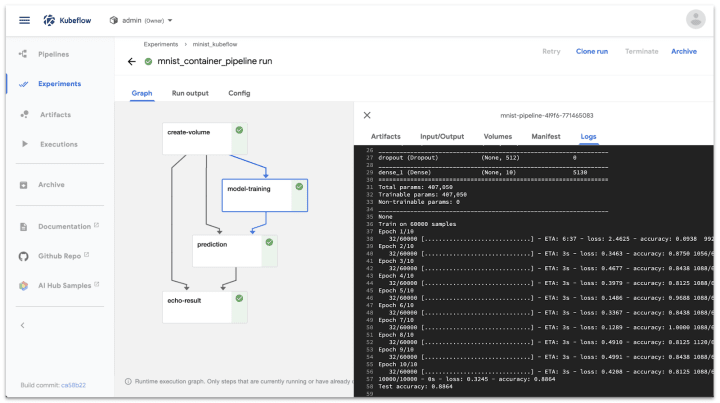
This way, experiments allow you to save and compare the results of your runs, keep your best performing models, and version control your workflow.
That’s it for this part!
In Part 2, we will create the pipeline you see on the last image using the Fashion MNIST dataset and the Basic classification with Tensorflow example, taking a step-by-step approach to turn the example model into a Kubeflow pipeline, so that you can do the same to your own models.
Further reading
To keep on learning and experimenting with Kubeflow and Kubeflow Pipelines:
- Watch the webinar on building Kubeflow Pipelines.
- Play with Kubeflow examples on GitHub.
- Read our Kubernetes for data science: meet Kubeflow post.
- Visit ubuntu.com/kubeflow
How to try Kubeflow?
To deploy Kubeflow on your Windows, macOS, or Ubuntu machine follow one of these:
This blog series is part of the joint collaboration between Canonical and Manceps.
Visit our AI consulting and delivery services page to know more.
Run Kubeflow anywhere, easily
With Charmed Kubeflow, deployment and operations of Kubeflow are easy for any scenario.
Charmed Kubeflow is a collection of Python operators that define integration of the apps inside Kubeflow, like katib or pipelines-ui.
Use Kubeflow on-prem, desktop, edge, public cloud and multi-cloud.
What is Kubeflow?
Kubeflow makes deployments of Machine Learning workflows on Kubernetes simple, portable and scalable.
Kubeflow is the machine learning toolkit for Kubernetes. It extends Kubernetes ability to run independent and configurable steps, with machine learning specific frameworks and libraries.
Install Kubeflow
The Kubeflow project is dedicated to making deployments of machine learning workflows on Kubernetes simple, portable and scalable.
You can install Kubeflow on your workstation, local server or public cloud VM. It is easy to install with MicroK8s on any of these environments and can be scaled to high—availability.
Newsletter signup
Related posts
Accelerating AI with open source machine learning infrastructure
The landscape of artificial intelligence is rapidly evolving, demanding robust and scalable infrastructure. To meet these challenges, we’ve developed a...
Unlocking Edge AI: a collaborative reference architecture with NVIDIA
The world of edge AI is rapidly transforming how devices and data centers work together. Imagine healthcare tools powered by AI, or self-driving vehicles...
How to deploy Kubeflow on Azure
Kubeflow is a cloud-native, open source machine learning operations (MLOps) platform designed for developing and deploying ML models on Kubernetes. Kubeflow...