
Four Challenges for ML data pipeline

Hugo Huang
on 9 April 2023
Tags: Data Pipeline , Google Cloud , high availability , machine learning , Ubuntu Pro
Data pipelines are the backbone of Machine Learning projects. They are responsible for collecting, storing, and processing the data that is used to train and deploy machine learning models. Without a data pipeline, it would be very difficult to manage the large amounts of data that are required for machine learning projects.
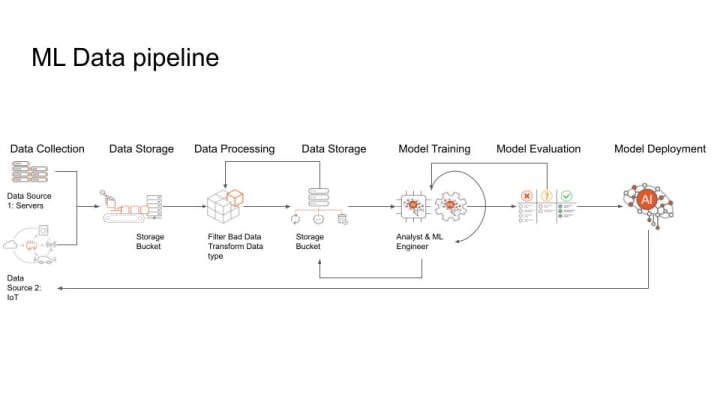
For this long, complex, fragile ML data pipeline, as we illustrated in the diagram, there are four major challenges for Data Engineers and Data Scientists: Volume, Velocity, Variety, and Veracity. They are collectively known as 4”V”s.
Volume
Volume refers to the amount of data that needs to be processed, stored, and analyzed. As we can see from the diagram above, data sources for an ML project may come from millions of IoT sensors all over the world, thousands of servers from data centers across multiple regions, or billions of video clips uploaded by mobile devices. Imagine hundreds of thousands of sensors for self-driving cars, eg. Tesla, on roads around the world. ChatGPT was also trained on a massive dataset of text and code, including 175 billion parameters, which are the building blocks of the model that allow it to learn and understand language.
The volume of data matters in ML data pipelines because it affects the accuracy and performance of the model. A larger dataset will provide the model with more information to learn from, which can lead to a more accurate model. Additionally, a larger dataset can help to improve the performance of the model, by making it more robust to noise and outliers. However, such a large volume of data also associates the cost, complexity, and risks.
Velocity
Data often needs to be processed in near-real time, as soon as it reaches the system. You’ll probably also need a way to handle data that arrives late. The late-arrived data are more likely to have errors. That means you need to fix those errors or at least pick out those data points before they hit the training process. There are a number of factors that contribute to the velocity challenge of ML data pipelines. One factor is the increasing volume of data. Data is being generated at an unprecedented rate, and this is only going to continue in the future. This means that ML data pipelines need to be able to process more data than ever before.
There are a number of ways to address the velocity challenge of ML data pipelines. One way is to use parallel processing. Parallel processing allows multiple tasks to be performed at the same time, which can help to speed up the processing of data. You can use Kubeflow to parallel train your data at any scale. Kubeflow is also fully integrated with Google Dataflow.
Variety
Data could come in from a variety of different sources and in various formats, such as number, image, or even audio. Let’s still take Chat GPT as an example. GPT models are trained on large amounts of text data crawled from the internet, including news articles, blog posts, social media updates, and other types of web content. GPT models also ingest books and other long-form content. This type of data provides a more structured and coherent representation of language, which can help the models learn to generate more coherent and well-formed text. Besides, GPT models are trained on a variety of articles from different domains, such as science, technology, politics, and entertainment. Some of the GPT models are also trained on conversational data, such as chat logs.
With the benefit of more generative ML models, the variety of data sources also presents several challenges for data scientists. How to orchestrate the data in multiple structures? How to understand the nuance of the same word in different industries or topics? If your data have to be stored in different types of databases, such as SQL and NoSQL, how can you make your data pipeline-interface adjust to the difference? Last but not least, how to evaluate the performance of your model with different data structures? Many data scientists choose Ubuntu Pro as their host OS for its compatibility with most types of databases, including MySQL, PostgreSQL, Microsoft SQL Server, etc.
Veracity
Veracity refers to data quality. Data can be corrupted or inaccurate, and data pipelines need to be able to identify and correct this data. The accuracy and reliability of data are critical to the performance of an ML model. Because big data involves a multitude of data dimensions resulting from different data types and sources, there’s a possibility that gathered data will come with some inconsistencies and uncertainties. Data engineers and data scientists need to ensure that the data they are working with is valid, consistent, and free from errors, biases, and other issues that could compromise its accuracy and usefulness. Techniques such as data cleaning, data validation, and data quality control are commonly used to improve the veracity of data in a data pipeline.
To address the veracity challenge of ML data pipeline, data engineers and data scientists sort a variety of ways of data quality control, including High Availability, monitoring and auditing data, access control, fixing system vulnerabilities, etc. High Availability is one of the most effective ways to ensure data quality. High Availability in data quality refers to ensuring that data is available and accessible to users at all times, while also maintaining its quality. To achieve High Availability, the common key strategies include Data Replication, Redundancy, Load Balancing, Automated Monitoring & Alerting, and Regular Maintenance & Testing.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Ubuntu Pro 24.04 LTS Lands on Google Cloud: Power Up Your Cloud Experience
Exciting news for cloud enthusiasts and developers! Ubuntu Pro 24.04 LTS (Noble Numbat) is now available on Google Cloud, bringing a robust and secure...
Simplify security maintenance and compliance with Ubuntu Pro auto-attach for LXD guests
With the latest LXD release, Ubuntu Pro now supports auto-attachment for LXD guest instances, offering organizations a seamless way to extend Ubuntu Pro...
Ubuntu Confidential VMs Now Available on Google Cloud A3 with NVIDIA H100 GPUs
Organizations are racing to harness the transformative power of AI, but sensitive data privacy and model security remain critical roadblocks. What if you...