
An overview of machine learning security risks

Andreea Munteanu
on 10 May 2024
Data is at the heart of all machine learning (ML) initiatives – and bad actors know it. As AI continues to occupy the limelight of modern tech discourse, ML systems are becoming increasingly attractive targets for attack. With the Identity Theft Resource Center reporting a 72% spike in data breaches in 2023, it’s critical to take the proper precautions to ensure your ML projects don’t provide a back door to your data.
This blog gives an overview of machine learning security risks, highlighting the key threats and challenges. But it isn’t all doom and gloom; we’ll also explain best practices and explore possible solutions, including the role of open source.
The machine learning attack surface
Every technology is subject to security concerns, but the challenge is even greater with machine learning because of the lack of talent and the innovative applications of AI. Some of the security factors include:
- Data security: ML projects need a lot of data, which often includes highly sensitive data such as personal information, financial statements or geo-location points. ML systems need to bear that in mind right from the start in order to protect not only the organisation but also the privacy of people. This includes data privacy and security both in transit and at rest.
You can learn more about MLOps on highly sensitive data by watching our talk at Kubecon
Watch now- Tools security: The machine learning lifecycle is complex and it often includes several tools. In turn, these use a high number of packages, which can represent potential security gaps within the wider system. Insecure packages can give access to the machine learning model or even the data itself, which is a huge security risk. Enterprises should carefully build their ML architecture with best practices in mind, such that tools are up to date and the machine learning security risks are reduced.
- ML model security: ML models might not seem like an obvious target for security attacks, but your models represent your intellectual property, making model theft a very real danger. What’s more, attackers can intentionally damage the performance of your models by adding malicious data points or manipulating the model training phase. ML models need to be built with security concerns in mind, such that activities like model testing and validation for model drift are part of the usual lifecycle.
- Hardware security: ML projects are dependent on the computing power they use, which often comes from newer investments in additional hardware. The hardware supply chain, maintenance and firmware updates – or lack of regular updates – can all represent potential risks. Organisations should carefully consider their hardware supplier, as well as their maintenance strategy.
- End device security: ML models are deployed to millions of devices every year, and they have different architectures, security regulations, and capabilities. When you start running ML in production, it’s important to avoid unwanted access to edge devices, including access to the model both on the device and in transit. Edge devices can be particularly vulnerable without appropriate model packaging, updates and security restrictions. You can read more about it in our blog about edge AI.
- The human factor: At the end of the day, ML projects include a wide variety of professionals, such as solution architects, data analysts, data scientists, and data engineers. They have different skill sets and training, especially regarding the security concerns of an ML project. There is always a risk associated with the professionals who are part of the ML initiatives, so ensuring the appropriate training and tracking of their responsibilities is crucial.
The top four machine learning security risks
With so many moving parts and potential avenues of attack, machine learning projects are subject to a large number of security risks, and this number is only growing as more and more ML applications enter production. Here are the four most common threats you should be aware of.
Package security vulnerabilities
Depending on the regulations of each industry and organisation, companies must ensure that the software they use does not contain any critical or high vulnerabilities. However, ML projects often depend on thousands of packages, so it’s easy for vulnerabilities to slip through the cracks. These vulnerabilities can appear at all layers of the stack, from the operating system to the applications, and they can be major security risks when exploited maliciously. An infamous example in the AI space is ShellTorch, which exposed all the code used during development and enabled people to access the models.
To mitigate this risk, you should have a clear understanding of the packages that your ML projects use, as well as their dependencies. You should implement regular scans that report vulnerabilities and have a strategy for fixing them. This includes having regular updates and upgrades of the tools used, following the latest news and security updates and having a trusted advisor.
Data poisoning
Data poisoning can happen when data is used to train a model or product, and an outcome is altered to damage the system’s performance. New data is often introduced into the system, causing the model to learn something new that is both inaccurate and unintended. For example, if your training dataset includes surveillance camera footage, attackers might maliciously target it and use only red cars for a certain period of time to train the model maliciously. Even a small amount of incorrectly labelled data can affect the model’s performance, making it unreliable for production.
With a clear understanding of how data can be influenced by possible attackers, you can implement measures to mitigate these risks. A continuous re-training pipeline ensures models always stay up to date, while drift monitoring for both the model and the data can ensure that professionals are informed in a timely manner if a model’s accuracy or structure varies.
Adversarial attacks
These are the most commonly used types of attacks in the machine learning space, which involve tricking the ML model to give the desired result. They usually include input provided by the attacker, giving a specific expected output. They basically trick the system due to the low number of boundaries that ML systems often have. Adversarial attacks are hard to detect by the human eye and even monitoring systems, mostly because models do not also learn the decision boundary, which is used to separate different classes based on the features of the input.
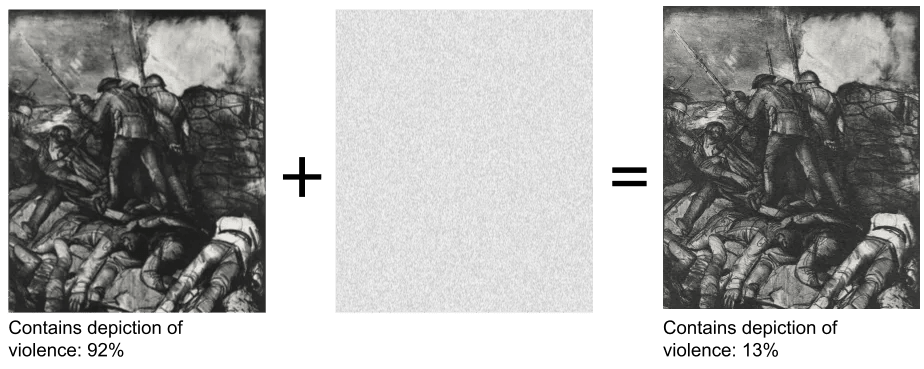
Adversarial attacks reduce the model accuracy and can cause professionals to avoid running any more certain projects in production. Organisations should consider adversarial training and have a clear strategy when building ML projects and cleaning data. Not all data that is produced should land directly in a training set. In addition, not everyone should have access to all models created within an organisation and capabilities such as experiment tracking, model stores and model performance trackers.
Data privacy
ML algorithms are built to predict or generate new data by only looking at the existing information. Companies, compared to individuals, have access to the personal data of millions of people. Whenever data is given access to an ML system, there is a risk associated with its confidentiality because of the new workflows it involves.
Organisations should build a clear privacy policy that all users should read and agree on and create ML systems that protect everyone. They should also be mindful of the data they gather and the processes involved in it. Best practices, such as removing identifiers and clear visibility of the data flows, will protect the privacy of both organisations and people who interact with it.
Best practices to improve your machine learning security
The four threats outlined above are just some of the machine learning security risks that projects face. They stand alongside the traditional software threats that are always present in any technology. As such, protecting your ML systems requires a specialised approach that considers the unique risks present in the AI space while also drawing on broader security best practices:
- Architect your ML systems with security in mind. The enthusiasm to start quickly can tempt professionals to skip steps and focus on building ML models. Temper your excitement and ensure that you build ML systems that are compliant and follow security regulations. From always keeping the packages up to date to building pipelines that are isolated, architects need to look at the big picture.
- Use data encryption. It will protect your data from possible attacks and avoid reducing the accuracy of a model. Data encryption alone is not enough to protect an ML system, but it is a foundational step for securely running ML projects in production.
- Look for anomaly detection and bias detection: Once a model runs in production, it is subject to error, which can impact the credibility or activity of an organisation. Anomaly detection or bias detection improves the robustness of an ML project, avoids falsely detecting any drift, and increases the chances of identifying any threat in a timely manner.
- Isolate your networks : Not everyone should have access to all ML pipelines, especially when projects use highly sensitive data. Professionals should always work on isolated networks that limit both access to the pipelines from outside and inside. It protects the data used through the pipelines and the project’s reliability.
- Control access: As ML projects grow within an organisation, so does the number of data scientists or ML engineers involved. It is important to control their access because of the projects that might be developed by some team members. For example, not everyone in a data science team might have approval to work on the financial data of the organisations. Also, there is a need to track any malicious activity that might come within the company. User management capabilities are crucial to the system’s visibility.
- Follow secure design principles. ML systems are new, but they should not be an exception to following existing best practices related to security. They should follow the existing secure design principles, and ask for specialised help when needed. In addition, you should always keep in mind the tasks you need to do to check the security of the systems, including threat modelling, static code analysis and CVE patching.
- Monitor your tools and artefacts. Having visibility of data, models, tools and packages involved in an ML project can determine its long-term success. Running daily scans of the tools, monitoring for data drift, and having constant visibility over the model performance are basic tasks that help professionals identify possible risks. In addition, you should develop a clear set of alerts, which inform everyone about any malicious attack or sudden change in behaviour for any of the artefacts.
- Educate your organisation. Artificial intelligence and machine learning are still new topics for most people. Organisations should spend time training professionals about their ML projects, their associated risks, and the methods they could use to report possible problems.
- Look at the entire machine learning lifecycle. Security can be a risk throughout the entire machine learning lifecycle, from data ingestion to model deployment. Protecting all artefacts throughout the journey will reduce the risks as attackers look for vulnerable parts of the pipelines. Vulnerabilities are often found towards the end of the cycle, in the deployment phase, but this should not encourage organisations to disregard the risks associated with the other steps.
Security solutions with open source AI
Open source is at the heart of development for machine learning. The Linux Foundation Data & AI shows the abundance of tools that data scientists, ML engineers, and architects have nowadays that are available to experiment and run their ML projects in production. It includes open source tools that are used to develop, deploy, monitor, or store models. Many of them focus on security, which we will further explore.

Canonical has open source in its DNA. The company’s promise is to provide secure open source software across all layers of the stack, from the operating system to the cloud-native applications. We will further explore how our security tools and capabilities enhance ML systems.
Livepatch
Livepatch is a solution that periodically checks for kernel patches and applies them to hardware without rebooting it. It enables organisations to update their hardware with the latest kernel patches, reducing downtime and unplanned work. This is also extremely useful when performing training for a longer period of time because of its ability to continue it without putting at risk the outcome or causing project delays. Additionally, it enables organisations to build and follow their own update strategy by planning the patching time and rollout policy. Ubuntu comes with Livepatch as part of Ubuntu Pro.
Confidential computing
Confidential computing originated in the late 1970s, but the rise of AI also accelerated its adoption. Using innovative technology at the silicon level, it protects the confidentiality and integrity of the sensitive data hosted on-prem or on a public cloud. Highly regulated industries such as healthcare or financial services often adopt it. Ubuntu is at the heart of confidential computing, being already available on Microsoft VMs or Intel TDX. Learn more about confidential computing.
Vulnerability fixes
New common vulnerabilities and exposures (CVEs) are coming up daily and need timely patching. Ubuntu Pro helps teams address this need in a timely manner by fixing over 30,000 packages as part of the subscription. This includes machine learning tools such as Pandas, Python, Numpy, Tensorflow or PyTorch, enabling professionals to develop models securely. Read more about how to secure your MLOps tooling.
MLOps platforms
Machine learning Operations (MLOps) platforms such as Charmed Kubeflow enable organisations to run AI at scale. They ensure that the ML systems have features such as authentication capabilities or network isolation to better control and protect data and ML models. They are a foundational piece to run the entire ML lifecycle within one tool, reducing the number of security holes that could appear throughout the ML pipeline.
Snaps for model packaging
Snaps are a secure and scalable way to embed applications on Linux devices. They can also be used for ML models that are packed and deployed to edge devices. It simplifies their maintenance and enables them to benefit from OTA updates and auto rollback in case of failure. Brand stores can also help you manage multiple models. Learn more about AI at the edge with open source.
ML systems are compelling targets for malicious actors, but that fact shouldn’t hold you back from innovating with AI. By developing a strong understanding of the threat landscape, implementing best practices, and taking advantage of open source solutions, you can protect your models and data and enjoy the benefits of AI/ML without putting your organisation at risk.
Explore Canonical’s secure, enterprise AI solutions.
Further reading
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Canonical joins OPEA to enable Enterprise AI
Canonical is committed to enabling organizations to secure and scale their AI/ML projects in production. This is why we are pleased to announce that we have...
Introducing Data Science Stack: set up an ML environment with 3 commands on Ubuntu
Canonical, the publisher of Ubuntu, today announced the general availability of Data Science Stack (DSS), an out-of-the-box solution for data science that...
Let’s meet at World Summit AI and talk about open source and AI tooling, with a dash of GenAI
Date: 9-10 October 2024 Booth: B8 After Data & AI Masters, we cross the North Sea to attend one of the leading AI events inEurope. Between the 9th and 10th of...